Tom Sandbox: Difference between revisions
No edit summary |
No edit summary |
||
| Line 13: | Line 13: | ||
===Structure=== | ===Structure=== | ||
GCN4 is composed of two identical 58 residue alpha helix chains that grouped together to form a parallel coiled-coil dimer. The dimer binds through interlocking leucine amino acids and hydrophobic residues near the C terminus, while pinching in on the major groove of DNA in the N terminal end via basic residues. These two main domains are thus labled the leucine zipper dimerization domain and the basic DNA-binding domain. <ref> Sharma, G.; Rege, K.; Budil, D. E.; Yarmush, M. L.; Mavroidis, C. Int J Nanomedicine. 2008 December; 3(4): 505–521. </ref> The basic residues are the reason the class of binding interactions is commonly referred to as bZIP or basic region leucine zipper proteins<ref name="Voet"> Voet, Donald; Voet, Judith G.; Pratt, Charlotte W. Fundamentals of Biochemistry: Life at the Molecular Level. 3rd Ed. Hoboken, NJ: Wiley, 2008. </ref>. The X-ray structure of the 33-residue polypeptide corresponding to the leucine zipper of GCN4 was determined by Peter Kim and Thomas Alber. | GCN4 is composed of two identical 58 residue alpha helix chains that grouped together to form a parallel coiled-coil dimer. The dimer binds through interlocking leucine amino acids and hydrophobic residues near the C terminus, while pinching in on the major groove of DNA in the N terminal end via basic residues. These two main domains are thus labled the leucine zipper dimerization domain and the basic DNA-binding domain. <ref name="ph"> Sharma, G.; Rege, K.; Budil, D. E.; Yarmush, M. L.; Mavroidis, C. Int J Nanomedicine. 2008 December; 3(4): 505–521. </ref> The basic residues are the reason the class of binding interactions is commonly referred to as bZIP or basic region leucine zipper proteins<ref name="Voet"> Voet, Donald; Voet, Judith G.; Pratt, Charlotte W. Fundamentals of Biochemistry: Life at the Molecular Level. 3rd Ed. Hoboken, NJ: Wiley, 2008. </ref>. The X-ray structure of the 33-residue polypeptide corresponding to the leucine zipper of GCN4 was determined by Peter Kim and Thomas Alber. | ||
====Heptad Repeat==== | ====Heptad Repeat==== | ||
| Line 29: | Line 29: | ||
====The Leucine Zipper==== | ====The Leucine Zipper==== | ||
The Leucine Zipper of GCN4, as expected, operates under a specific pH. It has been shown that at lower pH values the zipper will reversibly protenate and open up, losing its hydrophobic stability.<ref name="ph"/> | |||
Revision as of 06:33, 9 November 2011

| |||||||
| 2zta, resolution 1.80Å () | |||||||
|---|---|---|---|---|---|---|---|
| Non-Standard Residues: | |||||||
| |||||||
| Resources: | FirstGlance, OCA, RCSB, PDBsum | ||||||
| Coordinates: | save as pdb, mmCIF, xml | ||||||
GCN4 - The Leucine ZipperGCN4 - The Leucine Zipper
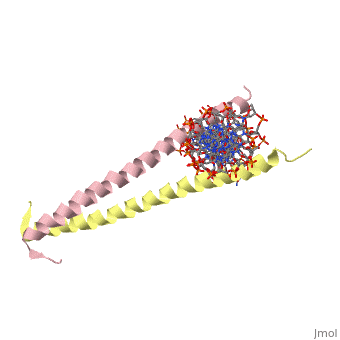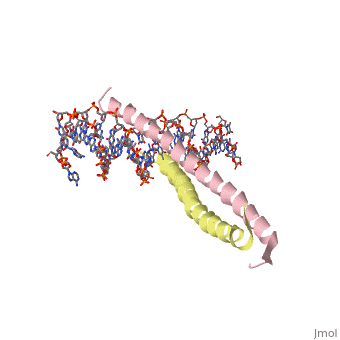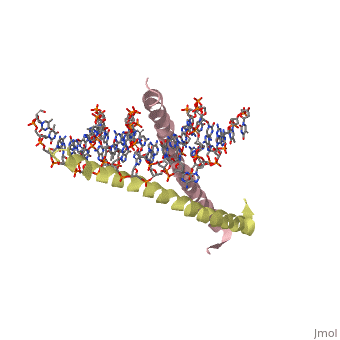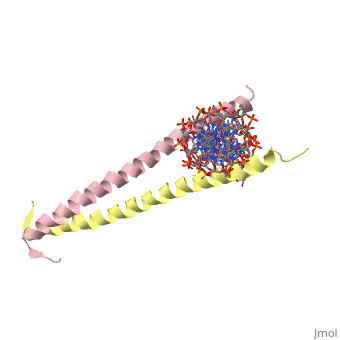
GCN4 (PDB 2zta by itself, 1ysa bound to DNA) is a eukaryotic transcription factor first isolated from Saccharomyces cerevisiae, also known as Baker's Yeast.
StructureStructure
GCN4 is composed of two identical 58 residue alpha helix chains that grouped together to form a parallel coiled-coil dimer. The dimer binds through interlocking leucine amino acids and hydrophobic residues near the C terminus, while pinching in on the major groove of DNA in the N terminal end via basic residues. These two main domains are thus labled the leucine zipper dimerization domain and the basic DNA-binding domain. [1] The basic residues are the reason the class of binding interactions is commonly referred to as bZIP or basic region leucine zipper proteins[2]. The X-ray structure of the 33-residue polypeptide corresponding to the leucine zipper of GCN4 was determined by Peter Kim and Thomas Alber.
Heptad RepeatHeptad Repeat
GCN4 is said to have a heptad repeat, or seven unit repeated sequence. Here the heptad repeat is a leucine, every seven units. When the structure of the alpha helices is taken into account, it is clear that each leucine is being stacked on top of the last one, every seven units. This creates the zipper-like repeated projections from the two polypeptide chains. Below we see a pictorial representation of the sequence of amino acids as we look down the length of the coiled coil structure.

Image 1:A pictorial representation of the heptad repeat between the two subunits in a coiled-coil conformation. By following through the wheels alphabetically, it is clear how the leucines will stack every 7 units. The apostrophe denotes the diference between the two polypeptide subunits.(from Kgutwin in Wikipedia Commons http://commons.wikimedia.org/wiki/File:Coiledcoil-wheelcartoon.gif)
At every d and d' we have a Leucine, while at the a and a' locations we typically see valine. [2] In the opposite positions one tends to see more charged and polar residues. The Leucine and Valine repeats create a strongly hydrophobic region between the two alpha helices.
The Leucine ZipperThe Leucine Zipper
The Leucine Zipper of GCN4, as expected, operates under a specific pH. It has been shown that at lower pH values the zipper will reversibly protenate and open up, losing its hydrophobic stability.[1]
| |||||||||
| 1ysa, resolution 2.90Å () | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| |||||||||
| |||||||||
| Resources: | FirstGlance, OCA, RCSB, PDBsum | ||||||||
| Coordinates: | save as pdb, mmCIF, xml | ||||||||